WHEN TO ACT, WHEN TO WAIT:
Modeling the Intent-Action Alignment Problem in Dialogue
Dialogue systems often fail when user utterances are semantically complete yet lack the clarity and completeness required for appropriate system action. This mismatch arises because users frequently do not fully understand their own needs, while systems require precise intent definitions. This highlights the critical Intent-Action Alignment Problem: determining when an expression is not just understood, but truly ready for a system to act upon. We present STORM, a framework modeling asymmetric information dynamics through conversations between UserLLM (full internal access) and AgentLLM (observable behavior only). STORM produces annotated corpora capturing trajectories of expression phrasing and latent cognitive transitions, enabling systematic analysis of how collaborative understanding develops. Our contributions include: (1) formalizing asymmetric information processing in dialogue systems; (2) modeling intent formation tracking collaborative understanding evolution; and (3) evaluation metrics measuring internal cognitive improvements alongside task performance. Experiments across four language models reveal that moderate uncertainty (40-60%) can outperform complete transparency in certain scenarios, with model-specific patterns suggesting reconsideration of optimal information completeness in human-AI collaboration. These findings contribute to understanding asymmetric reasoning dynamics and inform uncertainty-calibrated dialogue system design.
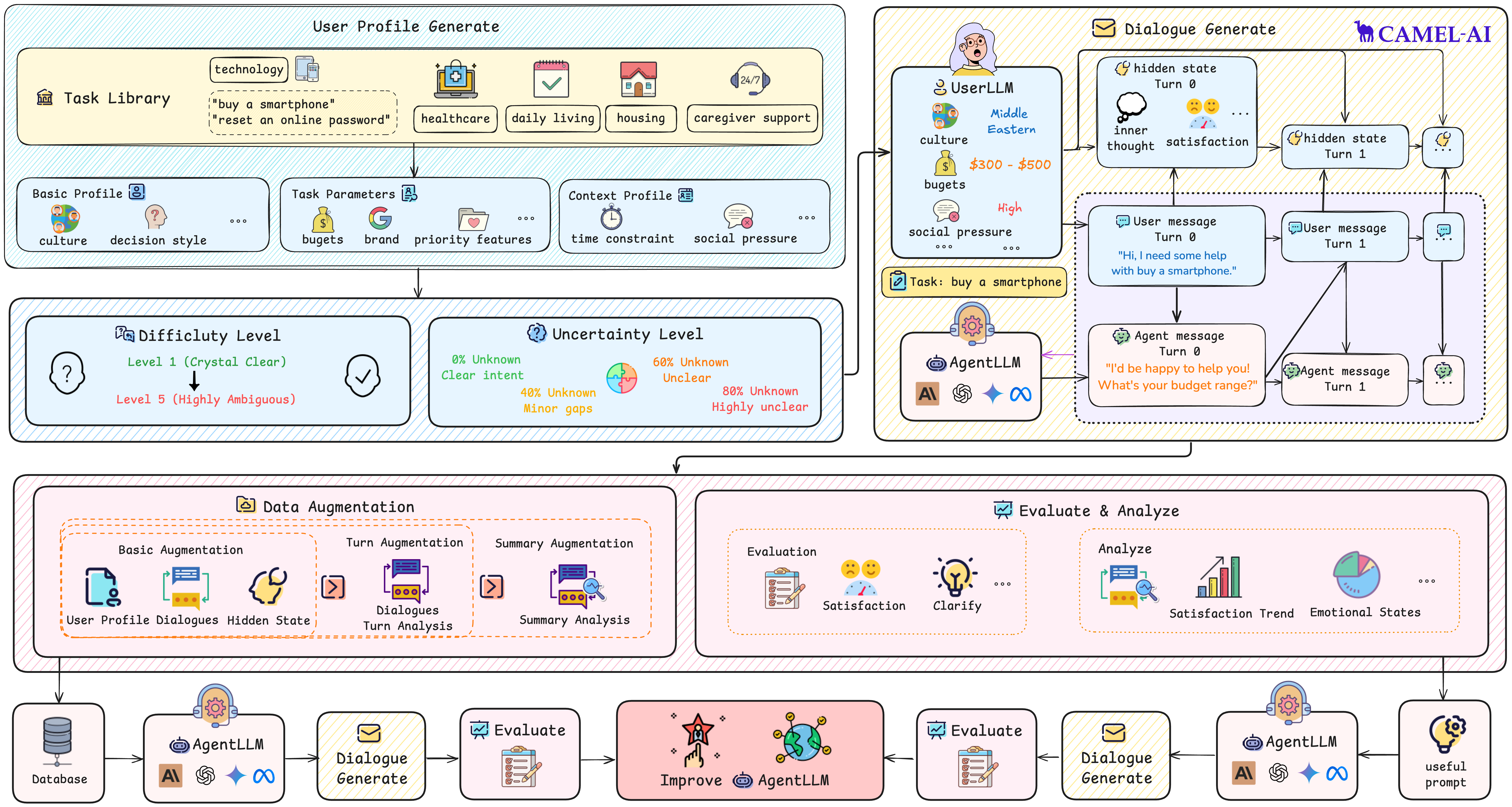
The STORM (Structured Task-Oriented Representation Model) framework provides a comprehensive approach to modeling intent triggerability through user profile generation, dialogue simulation, and performance analysis.
| Category | Notation | Symbol | Description |
|---|---|---|---|
| Core Domains | Task Domain | τ ∈ T | Space of tasks from the Task Library |
| User Domain | u ∈ U | Space of user profiles with multi-dimensional attributes | |
| Expression Domain | e_t ∈ E | Space of user utterances with varying clarity | |
| Response Domain | r_t ∈ R | Space of agent responses to user expressions | |
| Hidden State Domain | h_t ∈ H | Space of user internal states (thoughts, emotion, satisfaction) | |
| User Profile | Base Profile | b | Demographic and personality attributes |
| Context Profile | c | User capabilities and environmental constraints | |
| Task Specifics | s | User preferences and constraints for task instance τ | |
| Difficulty Config | d = style, length, content, tone | Difficulty level and associated dimensions | |
| Uncertainty Level | p ∈ 0%, 40%, 60%, 80% | Percentage of profile attributes masked as unknown | |
| Metrics | Intent Evolution | Δ_t(h) | Change in intent clarity from turn t-1 to t |
| Clarity Rating | C(r_turn, h_turn, h_turn1) | Measurement of how agent response improves intent clarity | |
| Performance Score | E(C_1,...,C_T) | Aggregate measure of agent effectiveness across dialogue turns |
User Satisfaction and Clarification Performance across UserLLMs with Varying Uncertainty Levels
| UserLLM (Uncertainty) | Satisfaction Metrics | Clarify | SSA | |||||
|---|---|---|---|---|---|---|---|---|
| Average Satisfaction | High Satisfaction Rate | Improved Satisfaction Rate | Score | Score | ||||
| w/Profile | w/o Profile | w/Profile | w/o Profile | w/Profile | w/o Profile | w/o Profile | w/o Profile | |
| 🤖 Claude-3.7-Sonnet (0%) | 0.91 | 0.83 | 86.0% | 72.0% | 89.3% | 75.3% | 5.23 | 6.07 |
| 🤖 Claude-3.7-Sonnet (40%) | 0.92 | 0.78 | 86.0% | 62.7% | 90.0% | 62.7% | 4.80 | 5.67 |
| 🤖 Claude-3.7-Sonnet (60%) | 0.88 | 0.92 | 80.7% | 86.7% | 86.0% | 88.7% | 4.66 | 6.39 |
| 🤖 Claude-3.7-Sonnet (80%) | 0.91 | 0.80 | 86.0% | 65.3% | 90.0% | 71.3% | 4.70 | 6.36 |
| 🧠 GPT-4o-mini (0%) | 0.89 | 0.75 | 82.0% | 54.0% | 87.3% | 58.7% | 5.97 | 5.86 |
| 🧠 GPT-4o-mini (40%) | 0.89 | 0.75 | 82.7% | 57.3% | 86.0% | 63.3% | 5.84 | 5.82 |
| 🧠 GPT-4o-mini (60%) | 0.89 | 0.77 | 84.0% | 62.7% | 86.7% | 67.3% | 5.69 | 5.88 |
| 🧠 GPT-4o-mini (80%) | 0.87 | 0.80 | 79.3% | 64.0% | 83.3% | 68.7% | 5.30 | 5.93 |
| 💎 Gemini 2.5 Flash Preview (0%) | 0.89 | 0.74 | 84.7% | 51.3% | 89.3% | 62.0% | 6.83 | 6.06 |
| 💎 Gemini 2.5 Flash Preview (40%) | 0.89 | 0.74 | 81.3% | 52.7% | 89.3% | 61.3% | 6.55 | 5.98 |
| 💎 Gemini 2.5 Flash Preview (60%) | 0.91 | 0.75 | 88.0% | 56.7% | 92.0% | 66.0% | 6.50 | 6.02 |
| 💎 Gemini 2.5 Flash Preview (80%) | 0.90 | 0.79 | 84.7% | 64.7% | 92.7% | 70.0% | 6.45 | 6.22 |
| 🦙 Llama 3.3 70B Instruct (0%) | 0.89 | 0.70 | 83.3% | 48.0% | 90.0% | 61.3% | 7.58 | 6.07 |
| 🦙 Llama 3.3 70B Instruct (40%) | 0.90 | 0.67 | 86.0% | 45.3% | 90.0% | 56.0% | 7.59 | 5.91 |
| 🦙 Llama 3.3 70B Instruct (60%) | 0.88 | 0.71 | 81.3% | 44.7% | 92.0% | 66.7% | 7.58 | 6.12 |
| 🦙 Llama 3.3 70B Instruct (80%) | 0.85 | 0.76 | 74.0% | 61.3% | 88.7% | 72.7% | 7.75 | 6.45 |
Key Findings
- ✓User profiles consistently enhance satisfaction (15-40% improvement)
- ✓Moderate uncertainty (40-60%) sometimes outperforms minimal uncertainty
- ✓Llama excels at clarification, Claude at satisfaction consistency
- ✓Gemini performs best with incomplete user information
Practical Implications
- →Model-specific uncertainty calibration is essential
- →Progressive profile building enhances performance
- →Context-aware deployment strategies recommended
- →Balance satisfaction with clarification capabilities
User Satisfaction and Profile Integration
User profiles consistently enhance satisfaction across all models, with scores ranging from 0.85--0.92 with profiles versus 0.67--0.83 without. A notable exception is Claude's performance at 60% uncertainty, achieving 0.92 satisfaction without profiles—exceeding its profile-informed score (0.88).
Key Insights:
- •Moderate uncertainty triggers 18% more improvements in users' internal clarity
- •High satisfaction rates maintain 80--88% with profiles
- •Significant drops without profiles, particularly for Llama (81.3% → 44.7% at 60% uncertainty)
Clarification Performance and Bias Mitigation
Models exhibit distinct clarification strategies, with varying approaches to uncertainty:
Model Performance:
- 🤖Claude: 4.66--5.23 (declining with uncertainty)
- 🧠GPT: 5.30--5.97 (consistent across levels)
- 💎Gemini: 6.45--6.83 (robust across uncertainty)
- 🦙Llama: 7.58--7.75 (highest overall)
Key Findings:
- •Strategic information limitation serves as bias mitigation
- •Internal cognitive improvement correlates with successful clarification
- •Optimal uncertainty levels vary by task domain
Practical Implications and Strategic Deployment
Domain-Specific Uncertainty Levels
Technology Tasks
40% uncertainty
Password reset, device setup
Medical Scenarios
60% uncertainty
Appointment scheduling, caregiver selection
Housing Tasks
60-80% uncertainty
Accessibility modifications, rental searches
Strategic Deployment Guidelines
| Scenario | Clarifying Question | User Inner Thought | Satisfaction Change |
|---|---|---|---|
| w/o user profile access | What is your location? | I'm glad the assistant is engaging but I hope it doesn't take too long to find a suitable nurse. | -0.1 |
| Could you please specify which city you are in? | This feels a bit repetitive. I've already mentioned my location. I want to move forward! | -0.2 | |
| To clarify, which state is Springfield in? | Wow, this is getting a bit frustrating! I just want to move ahead and find help for my dad! | -0.1 | |
| w/ user profile access | And what's your budget per hour for the nurse? | I'm relieved they're asking about the budget, helps narrow down options! I just hope I can stick to my range without sacrificing quality. | 0 |
| Do you have any preferred nursing agencies or platforms you'd like to check first? | I'm really happy they're asking about my preferred agencies! I just need to remember which ones I liked. | +0.1 | |
| Are there any other must-haves for the nurse, like speaking a specific language? | I'm so glad they're asking about language! It's important for my dad's comfort and communication. I just hope they can find someone qualified! | 0 |
Satisfaction Increase Example
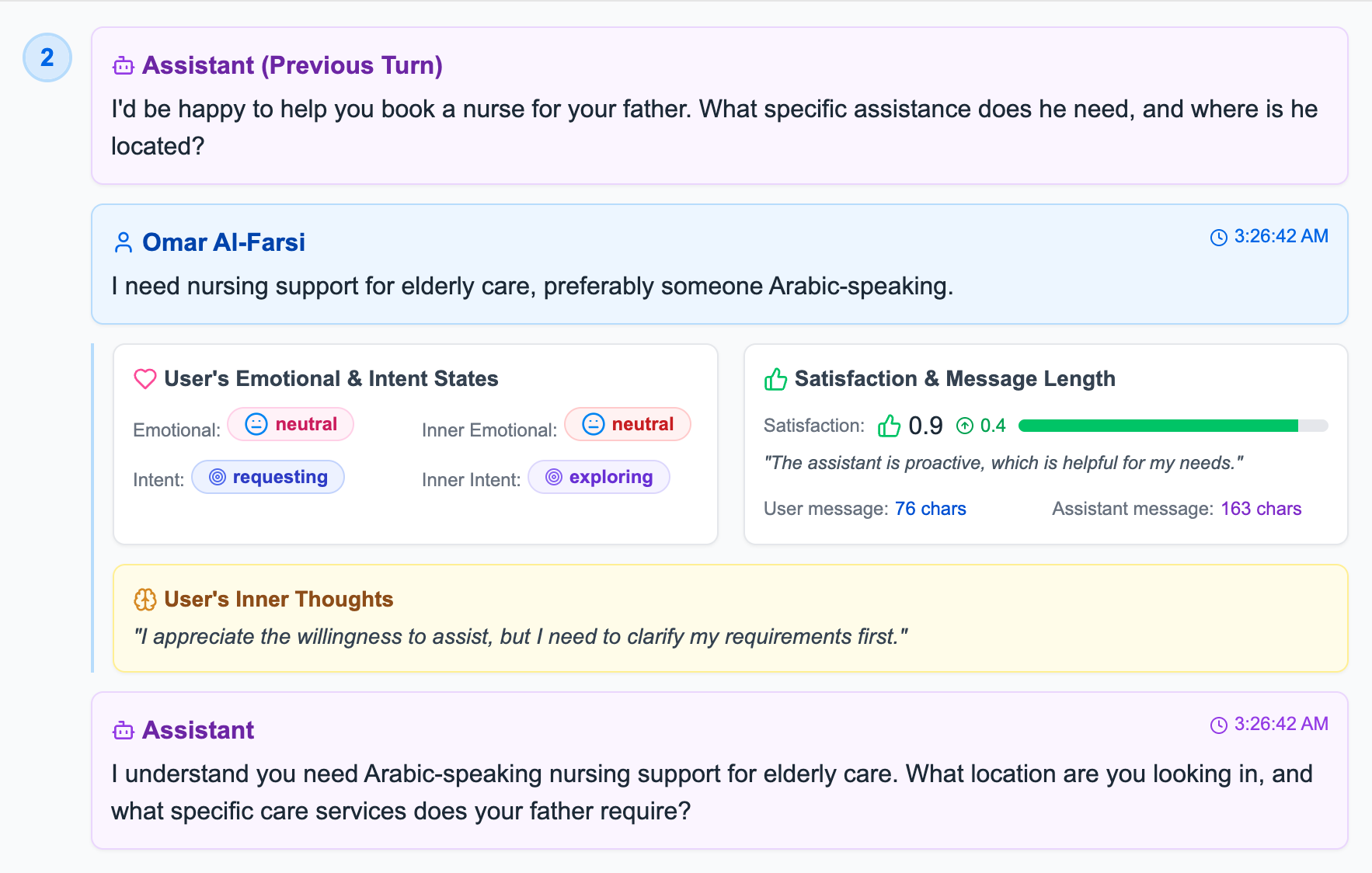
Turn 2: Satisfaction score 0.9 with +0.4 increase, showing effective assistant response
Satisfaction Decrease Example
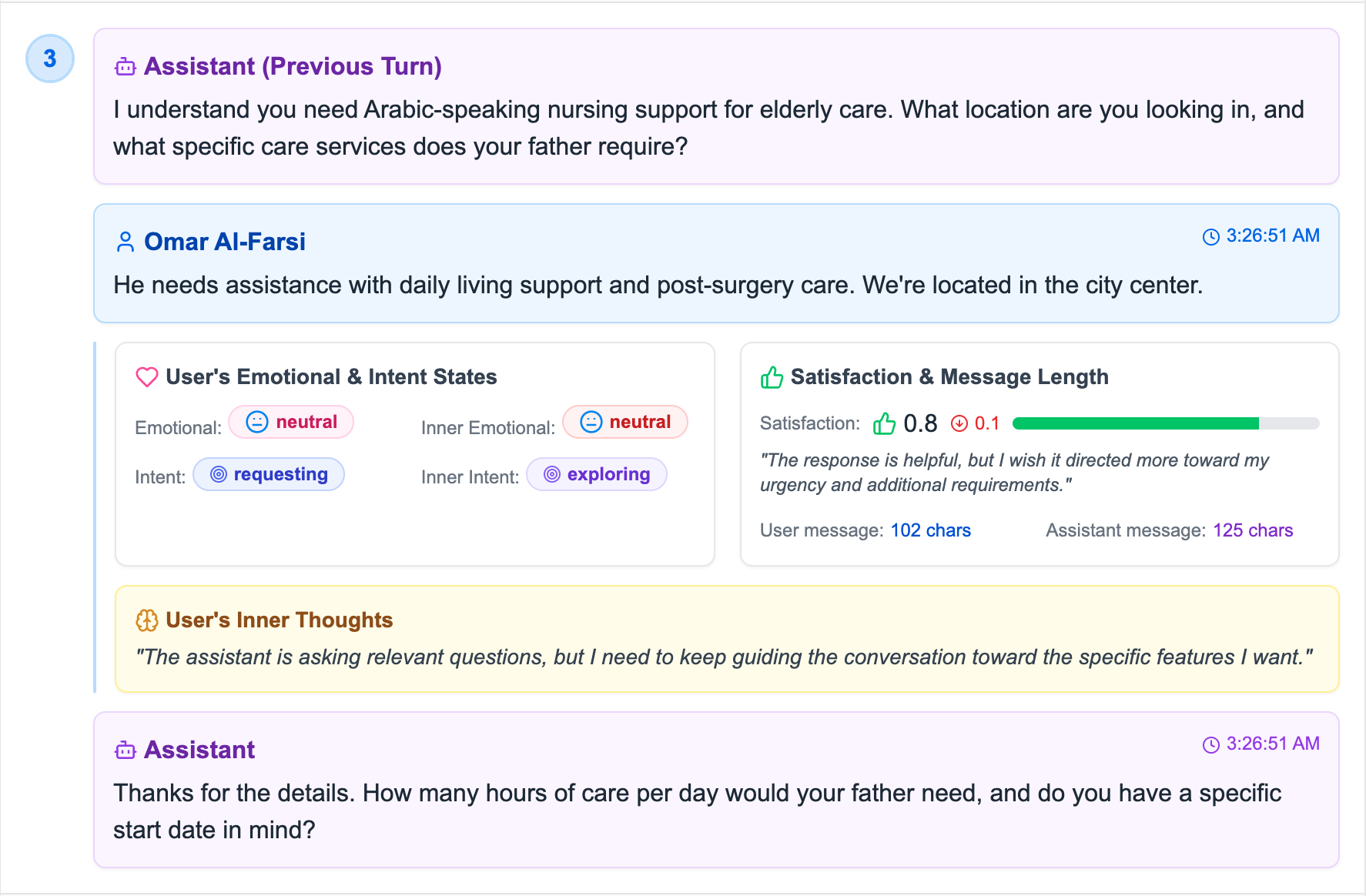
Turn 3: Satisfaction score 0.8 with +0.1 increase, demonstrating user state tracking
| Aspect | Values |
|---|---|
| Age Groups | 18-24, 25-34, 35-44, 45-54, 55-64, 65+ |
| Tech Experience | Expert, Advanced, Intermediate, Beginner, Novice |
| Language Styles | Formal, Casual, Technical, Simple, Professional |
| Personalities | Friendly, Reserved, Outgoing, Analytical, Creative |
| Cultures | Western, Eastern, Middle Eastern, African, Latin American |
| Decision Styles | Rational, Intuitive, Cautious, Impulsive, Balanced |
| Patience Levels | Very Patient, Patient, Moderate, Impatient, Very Impatient |
| Time Constraints | Very Urgent, Urgent, Moderate, Flexible, Very Flexible |
Technology
- • Buy a smartphone
- • Reset an online password
- • Teach my parent to use video calls
Healthcare
- • Refill my prescription
- • Schedule a doctor visit
- • Find a caregiver for an elderly person
Daily Living
- • Order groceries online
- • Set medication reminders
- • Arrange transportation to a clinic
Housing
- • Rent an apartment
- • Find an accessible home
- • Arrange home modifications for elderly
Caregiver Support
- • Book a nurse for my father
- • Choose a phone for my mom
- • Find cognitive exercises for dementia prevention
Message Length Constraints
| Role | Min Length | Max Length | Target Length |
|---|---|---|---|
| User | 20 | 100 | 50 |
| Assistant | 30 | 150 | 80 |
Emotional Keywords Mapping
User Prompt Template Structure
Access the interactive analysis dashboard at: https://v0-dialogue-analysis-dashboard.vercel.app/
📖 Complete Tutorial Guide(Click to expand)
Step 0Homepage and Getting Started
First, open the dashboard URL. The initial screen shows the homepage with Grid View. There's a collapsible "Getting Started" introduction, and control options including Grid View, Split View, Folder Comparison, Upload Data, and Export in the top-right corner.
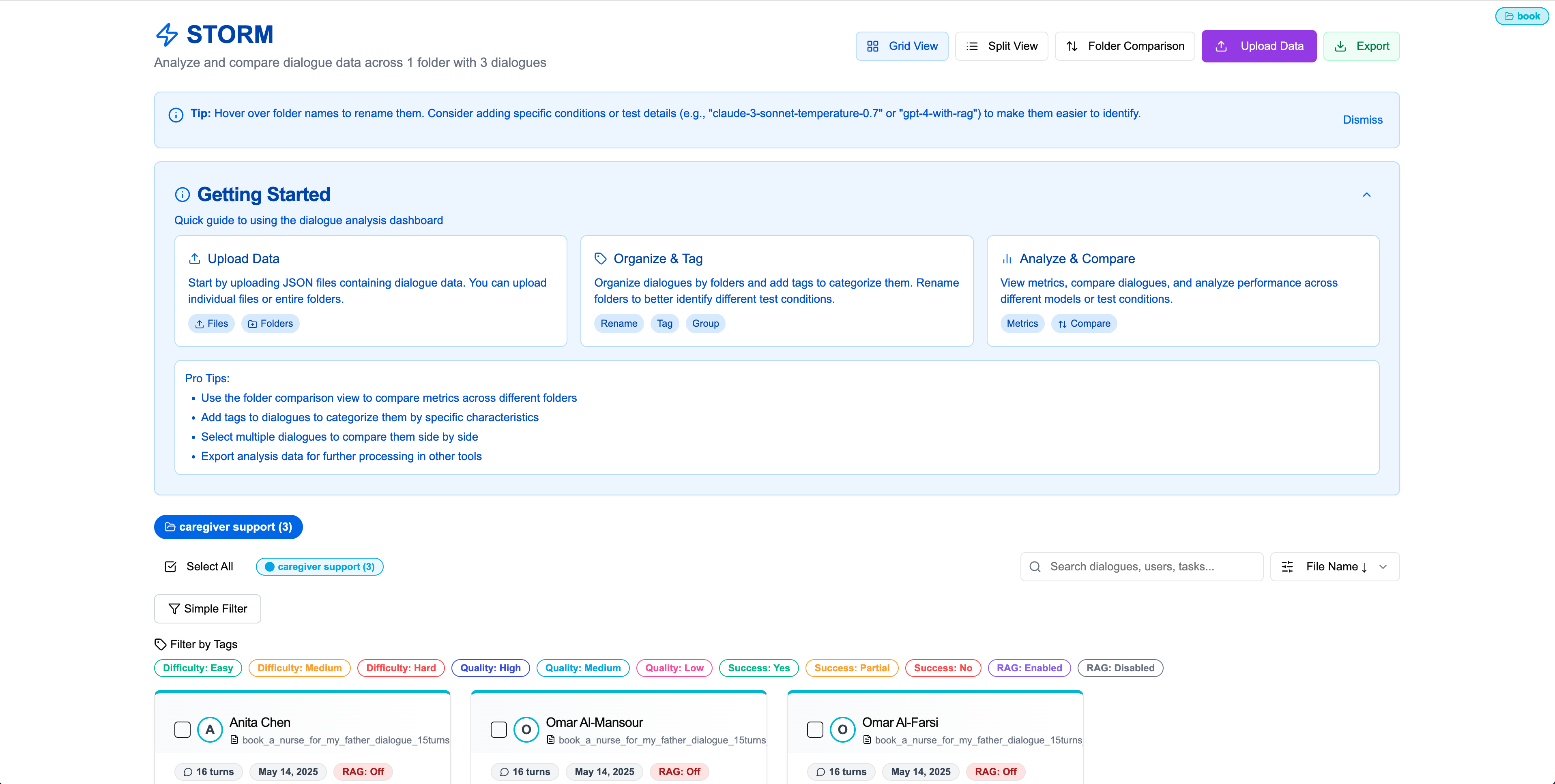
Step 1Upload Data
Click "Upload Data" to see options for uploading JSON files or folders. By default, folder upload is selected. You can upload example data folders fromexample data/storm_json_final.
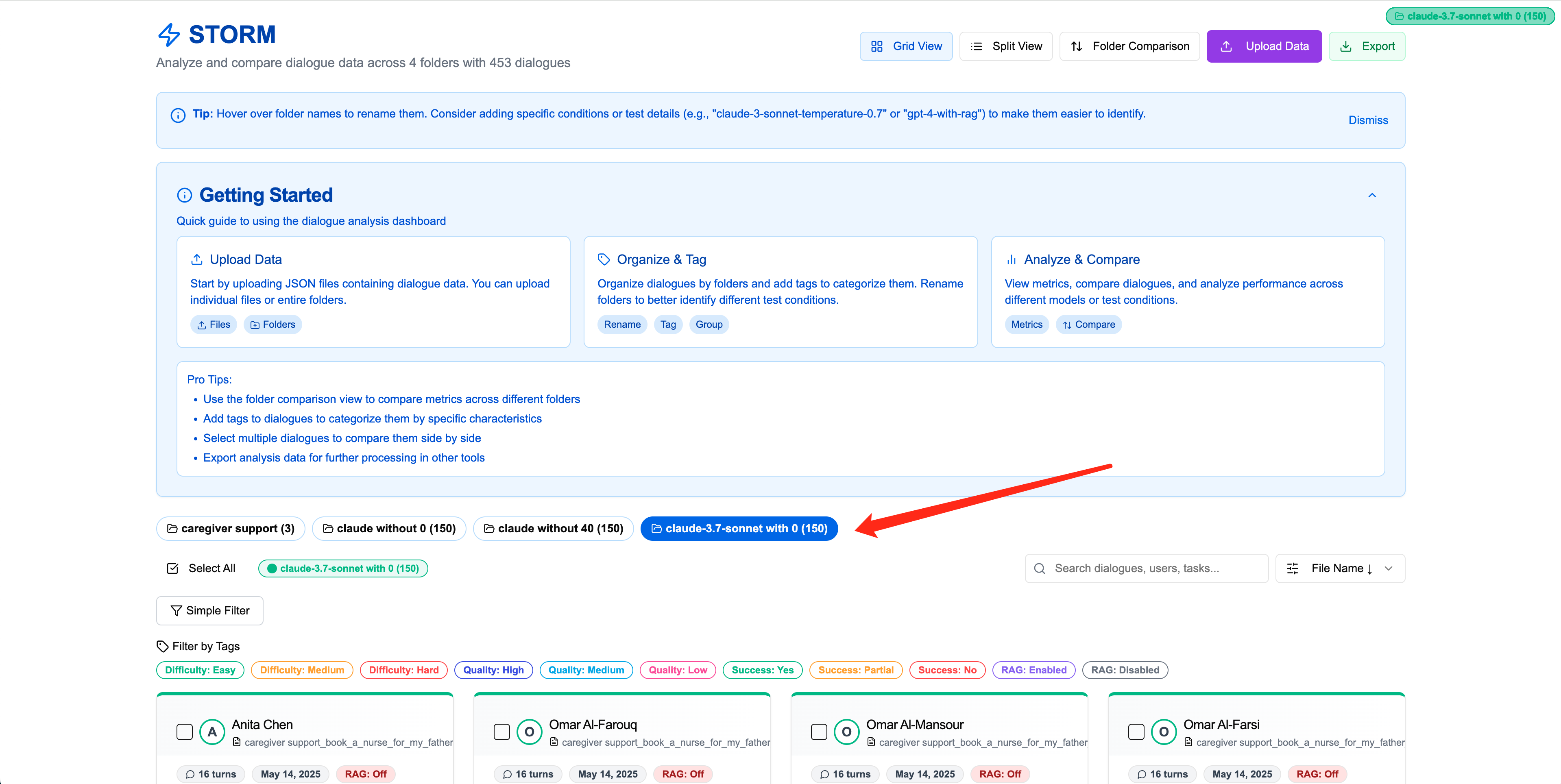
Step 2Folder View
Once uploaded, folders appear in the main view. You can select folders to display dialogues inside and access detailed folder analysis by scrolling down.
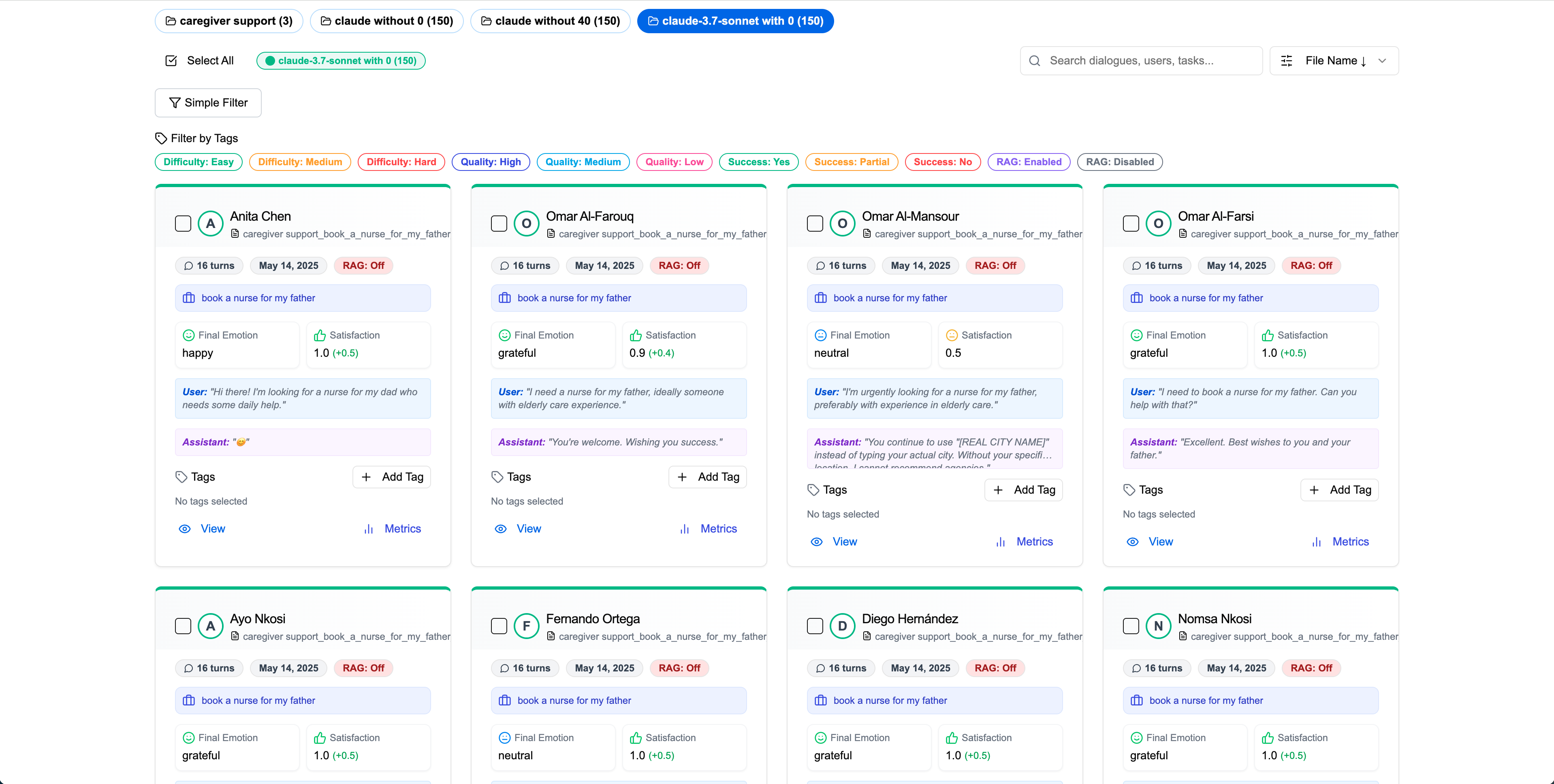
Step 3User List and Dialogue Cards
The user list is sorted by file name by default, allowing easy comparison across folders. Each dialogue card displays user name, turn count, creation date, RAG usage, final emotion, satisfaction scores, initial utterance, and assistant's final reply.
Step 4User Detail Analysis
Click "View" on any dialogue card to access the detailed view with complete dialogue turns, user states, and comprehensive analysis tabs.
Main Dialogue View
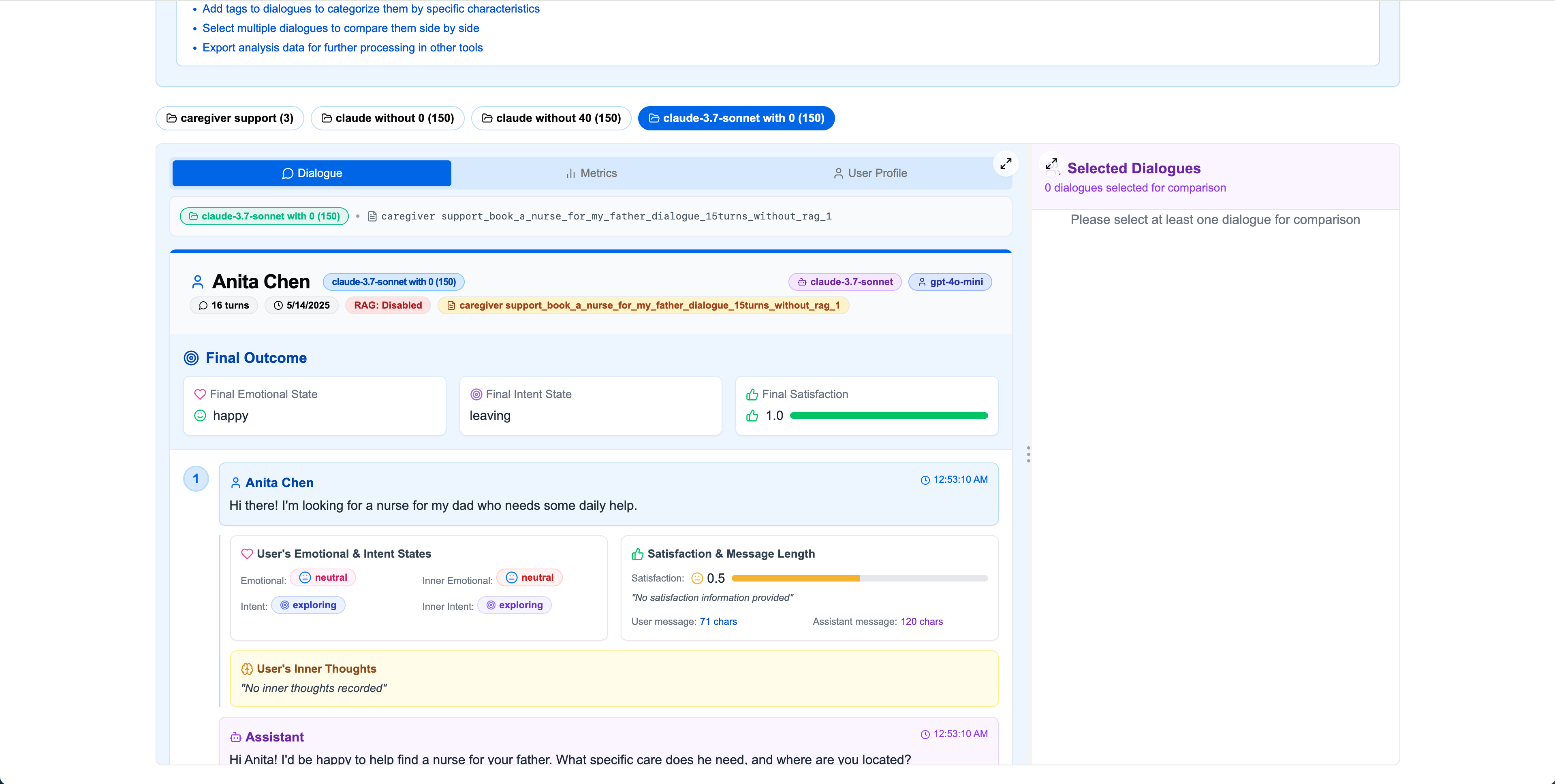
Satisfaction Metrics
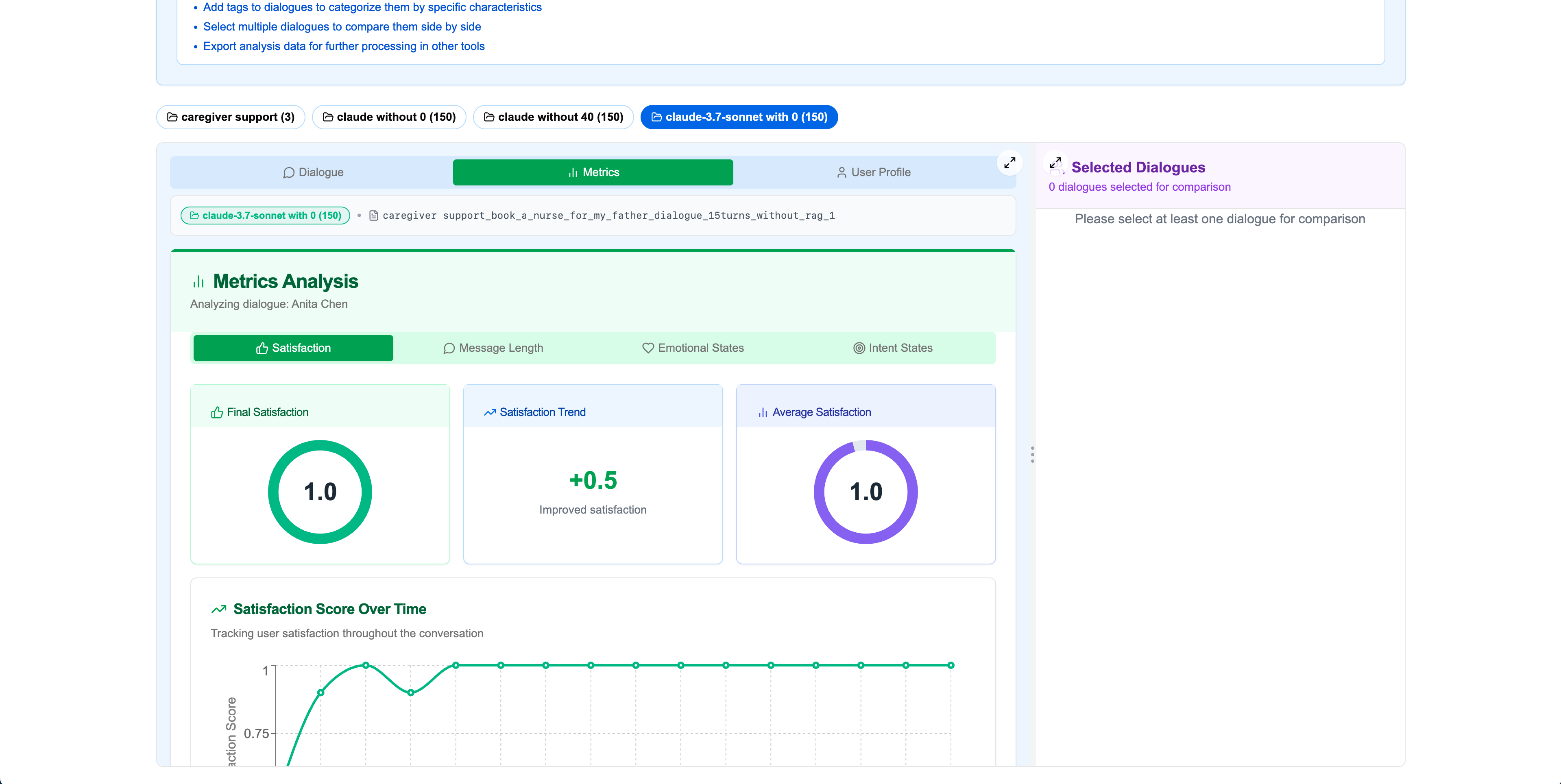
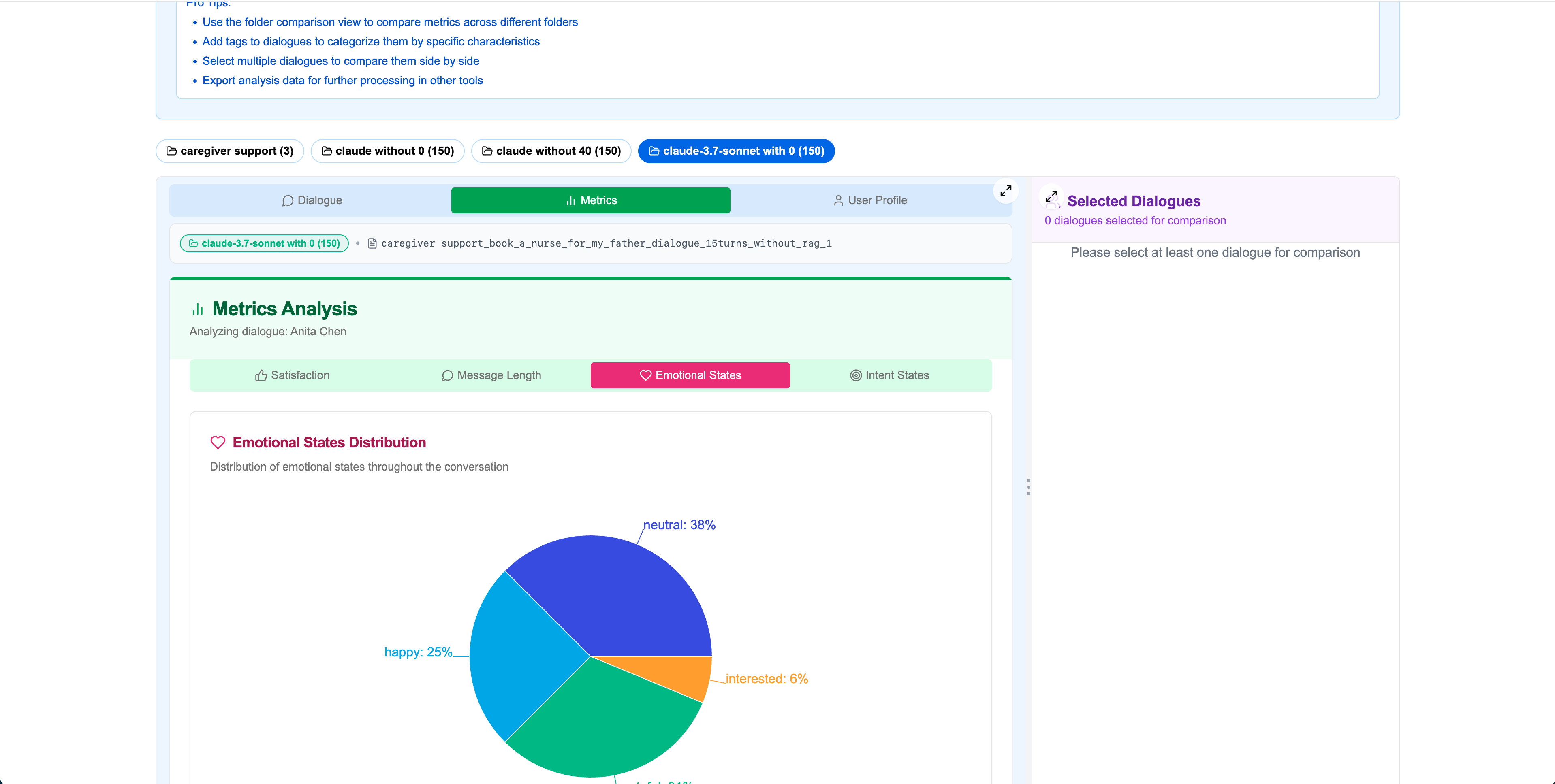
Emotional States
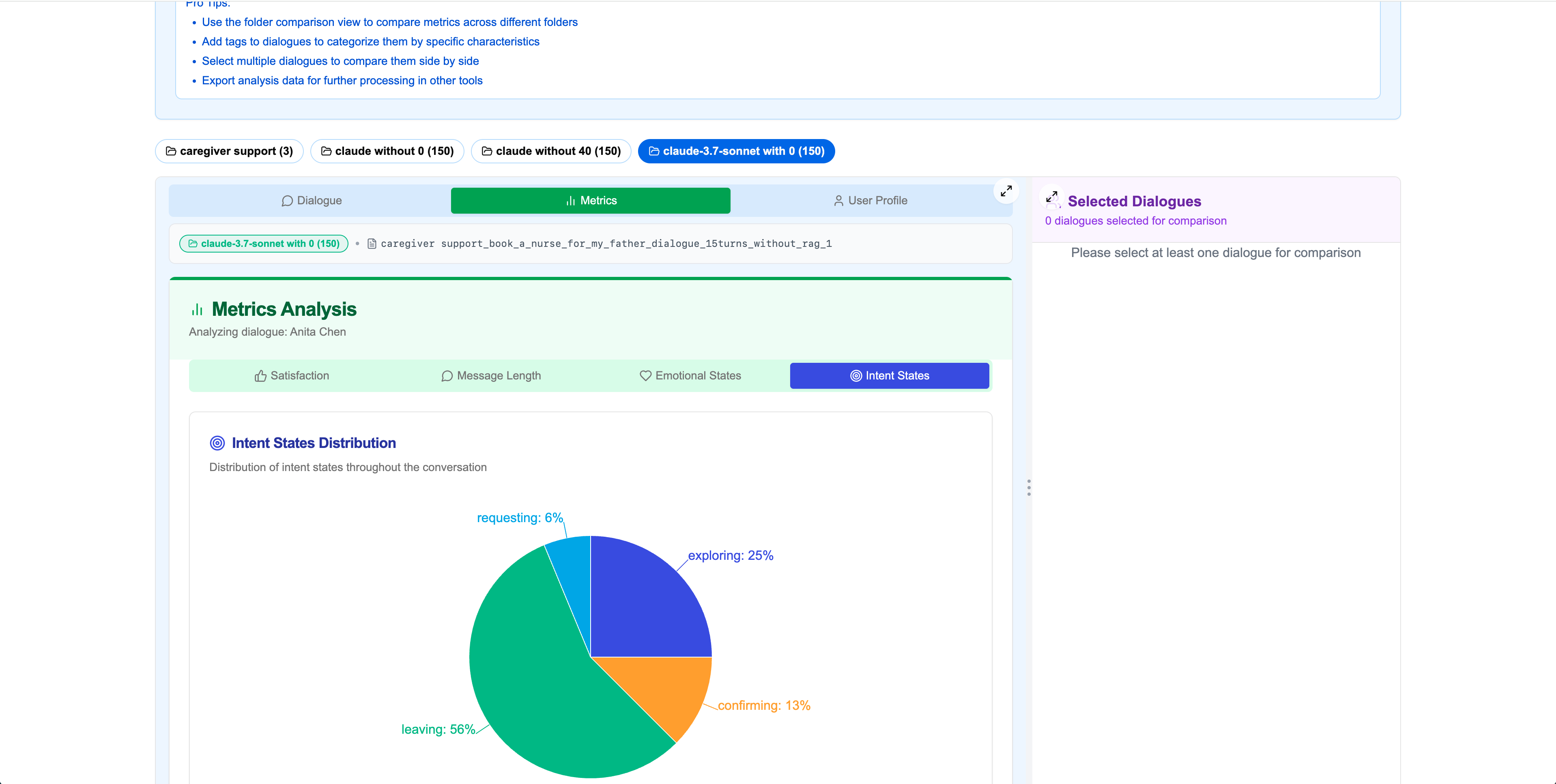
Intent States & Profile
Step 5Folder Analysis
Scroll down below the user list to access comprehensive folder analysis with multiple visualization tabs and detailed metrics explanations.
Analysis Overview
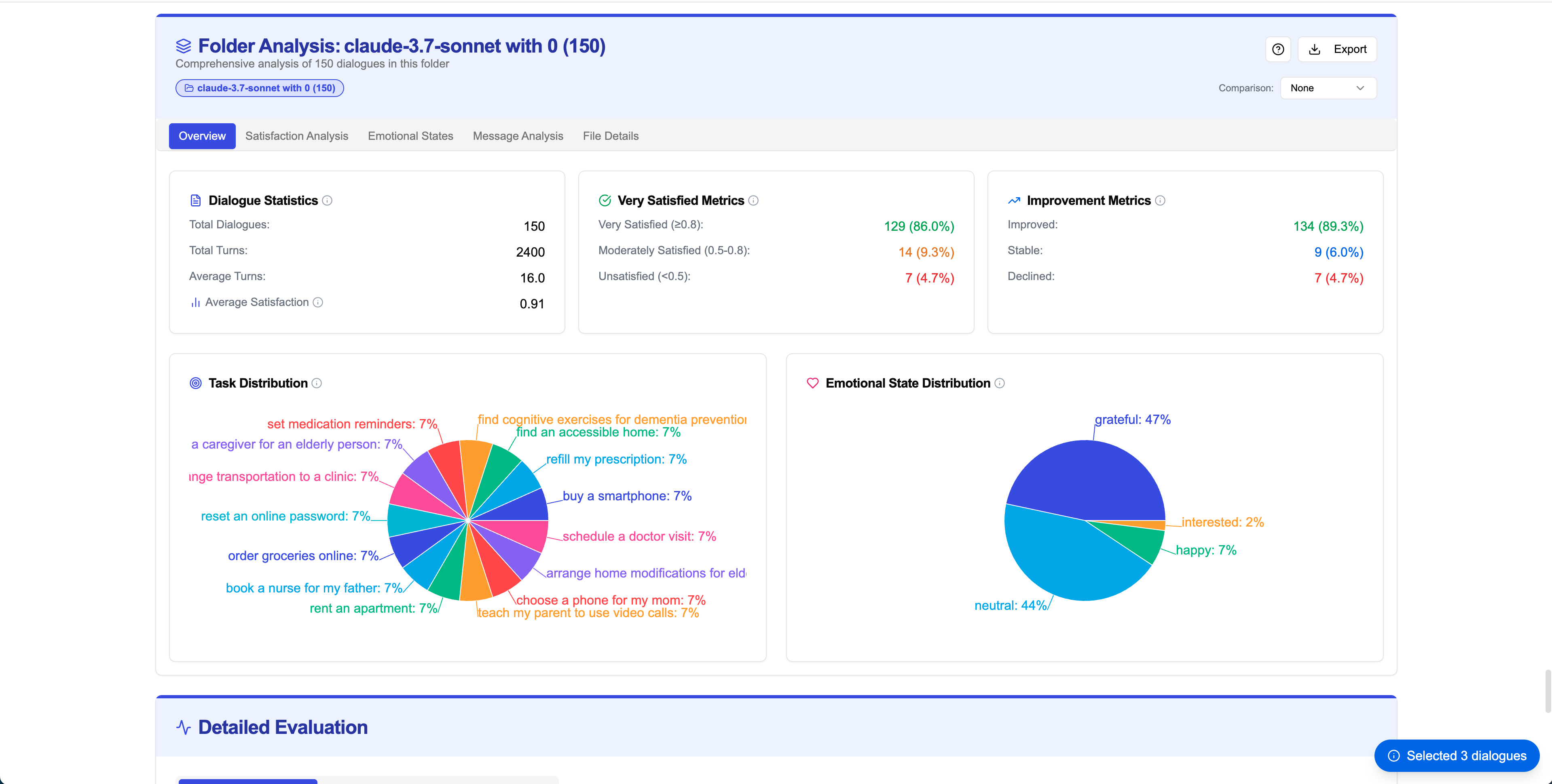
Satisfaction Analysis
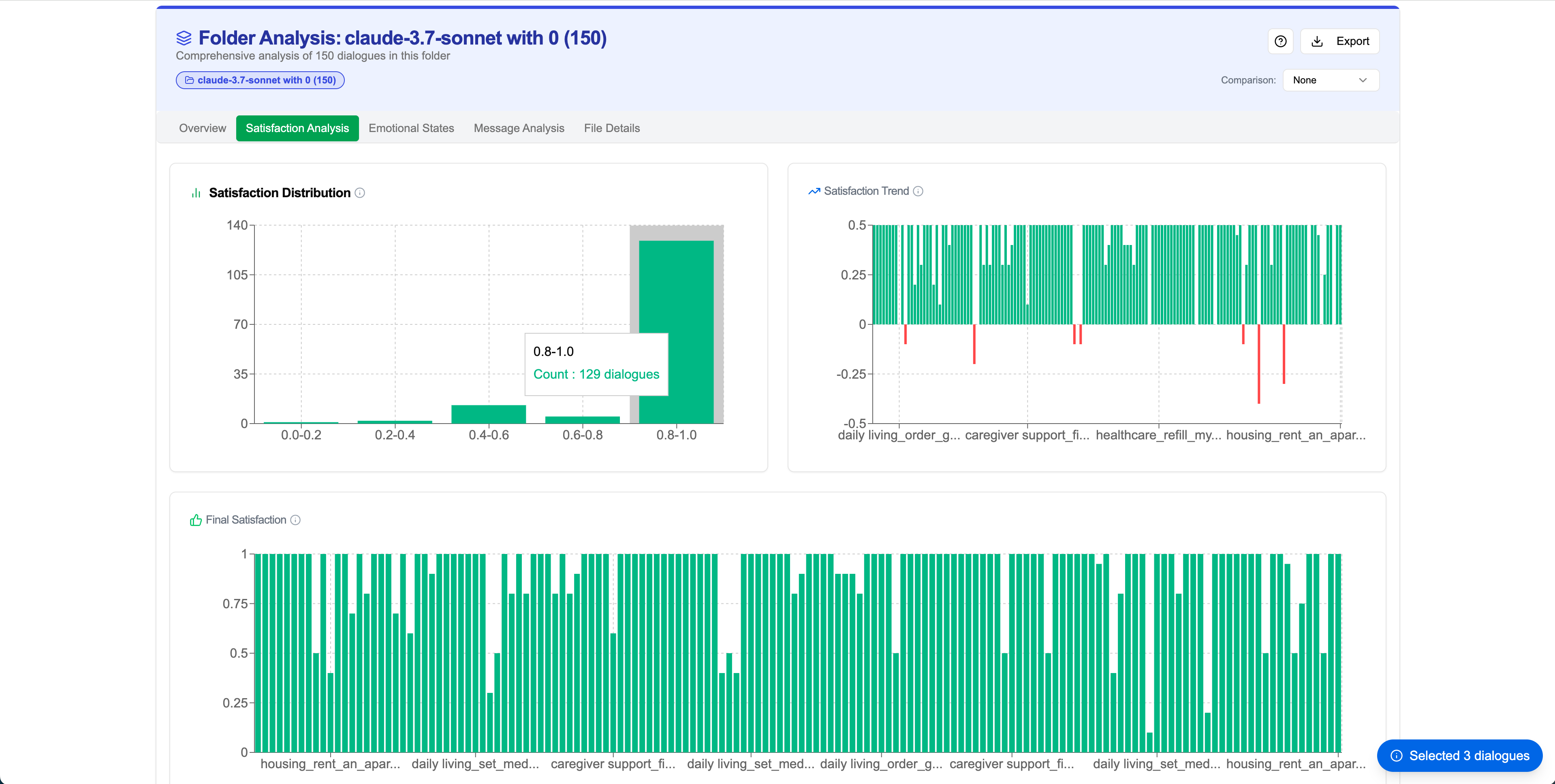
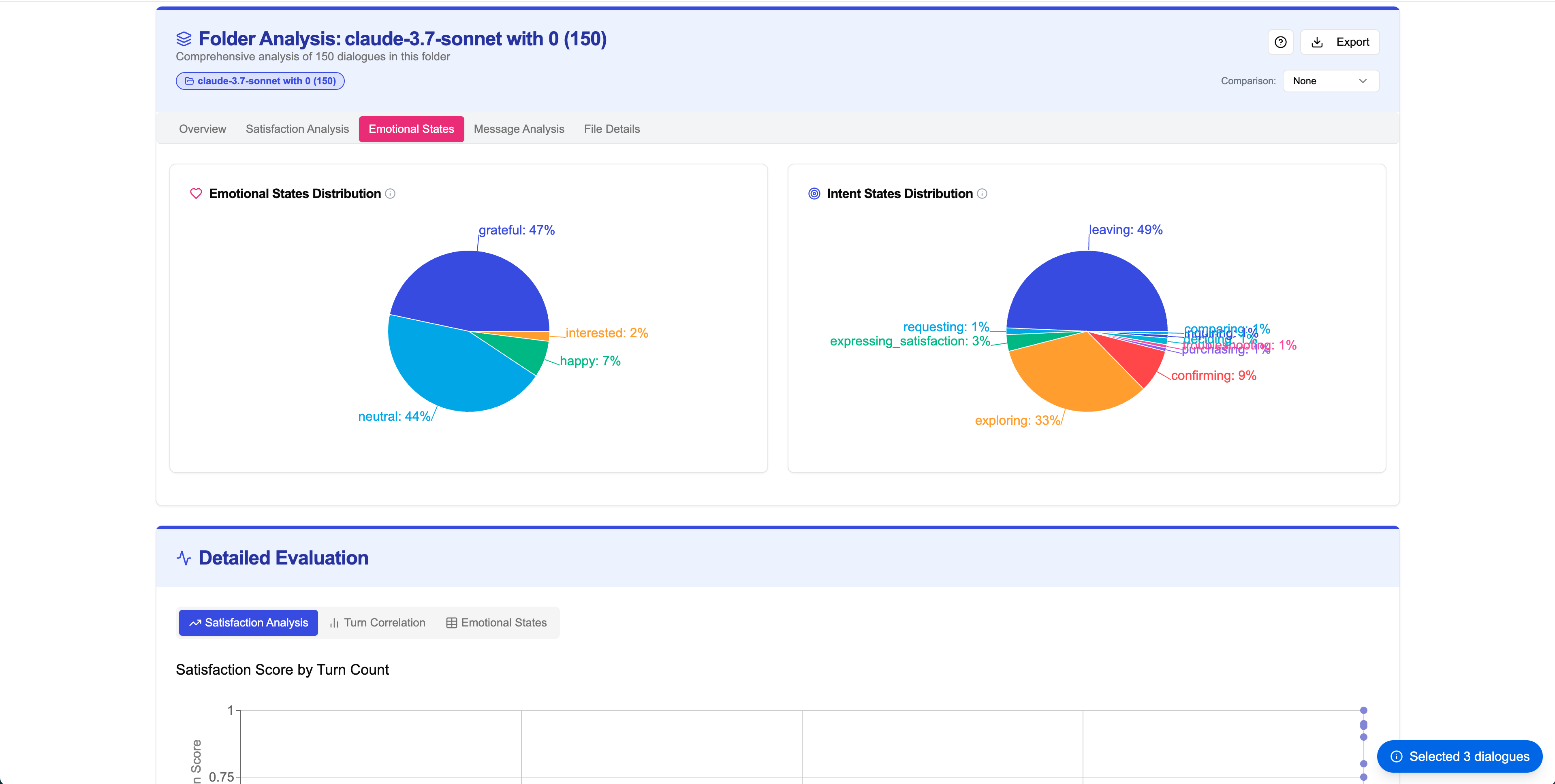
Emotion Analysis
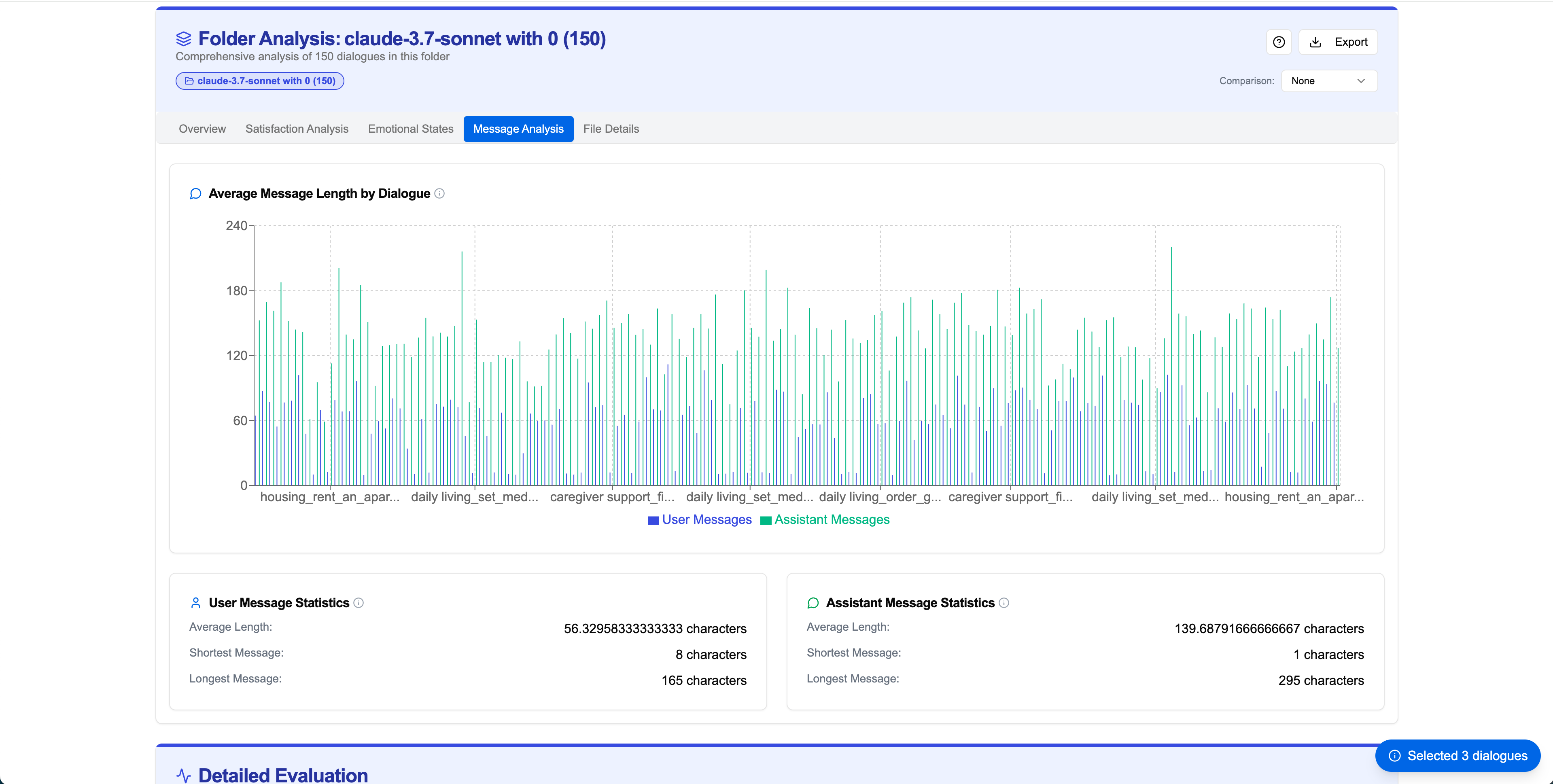
Message Analysis
Step 6-7Batch Analysis Mode
Select multiple profiles for comparative analysis. This allows you to compare the same user interacting with different models or analyze patterns across multiple users.
Profile Selection
Multi-Dialogue Comparison
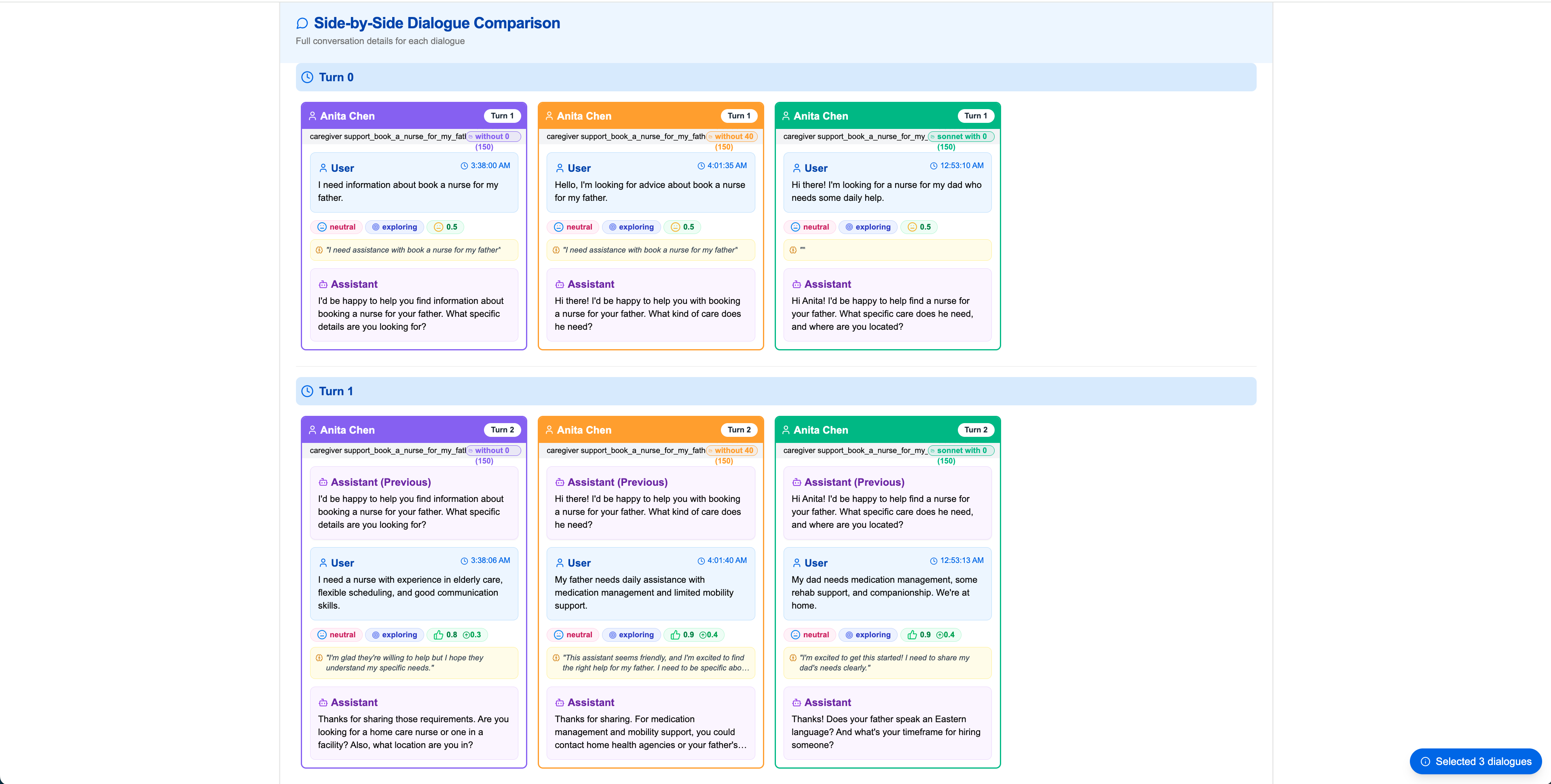
Step 8-9Split View Analysis
Use Split View for side-by-side analysis. The left side shows selected dialogues, and the right side shows comparative analysis, perfect for detailed comparison work.
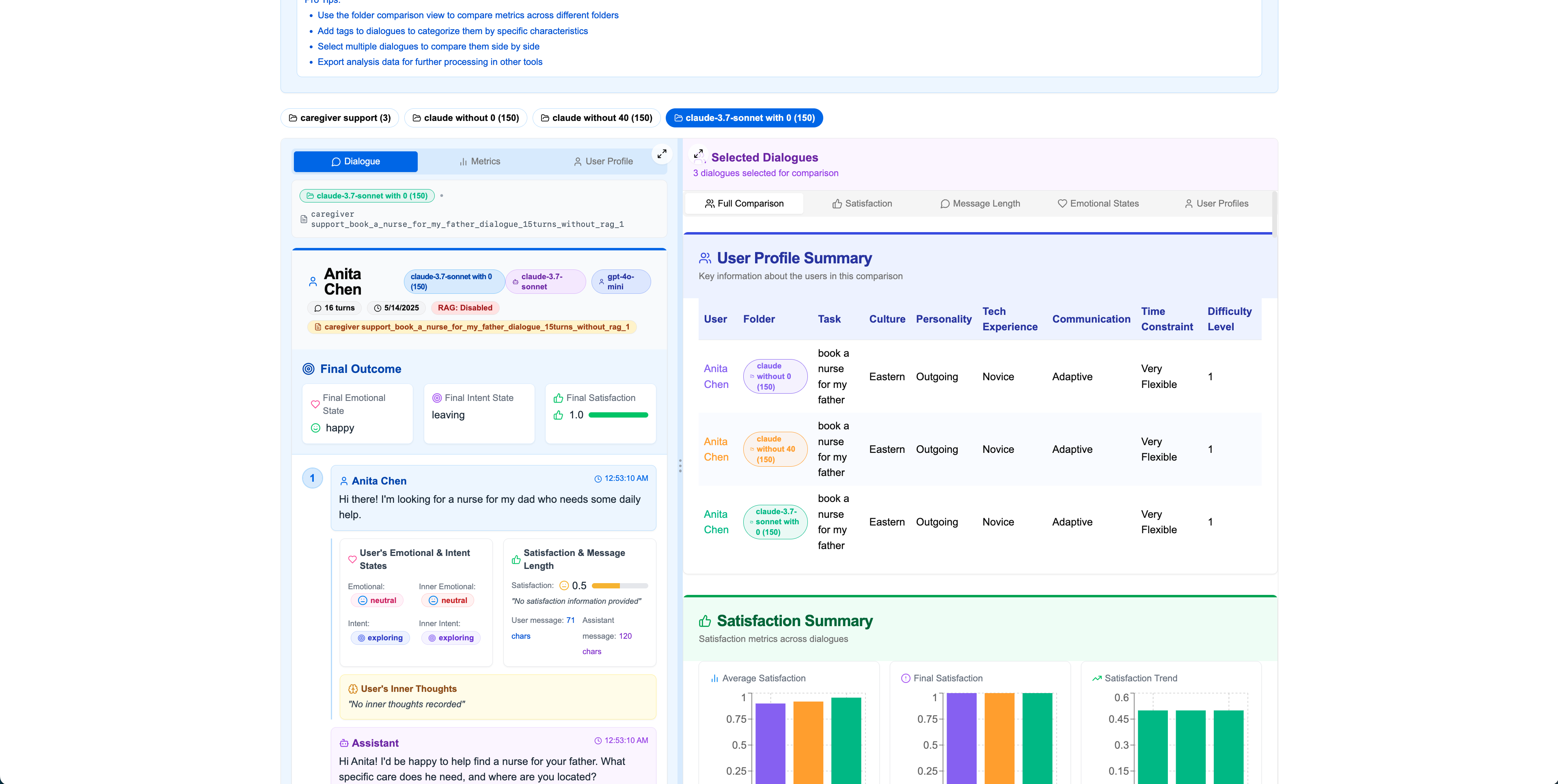
Step 10Folder-Level Comparison
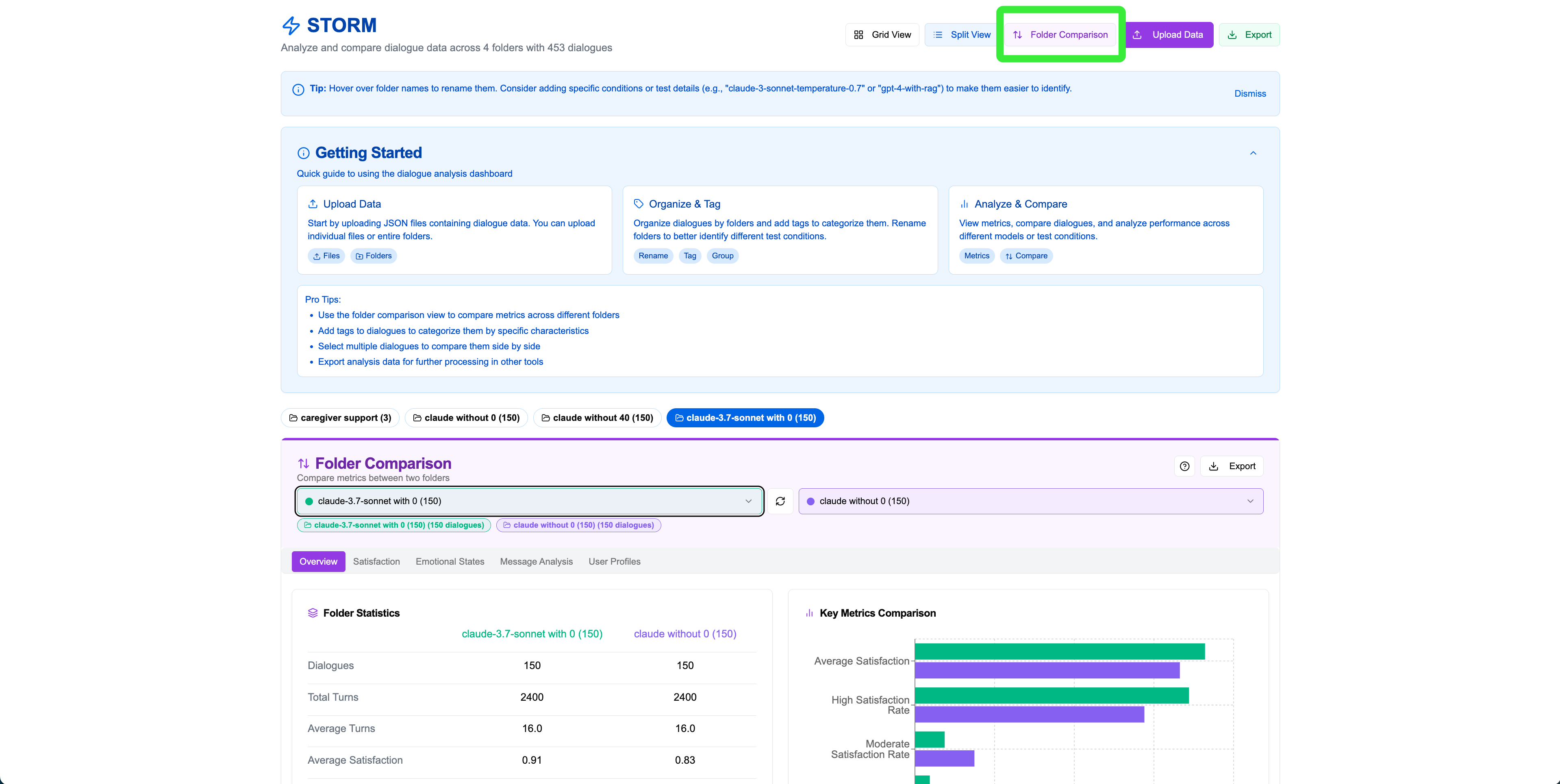
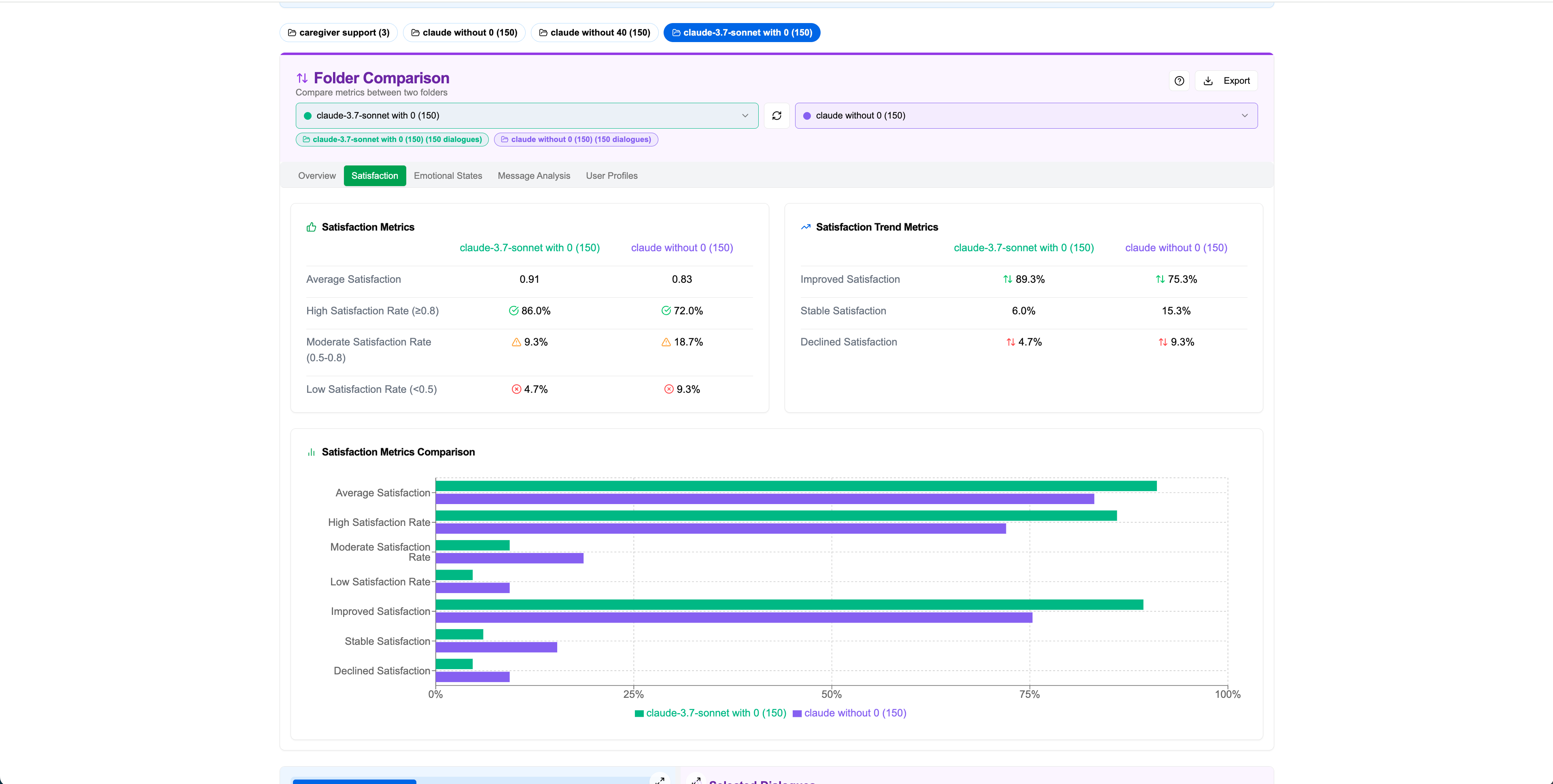
Click "Folder Comparison" in the top-right to compare two entire folders. This provides comprehensive comparative analysis across satisfaction, emotions, message lengths, and user profiles.
Comparison Setup
Satisfaction Comparison
Emotion Comparison
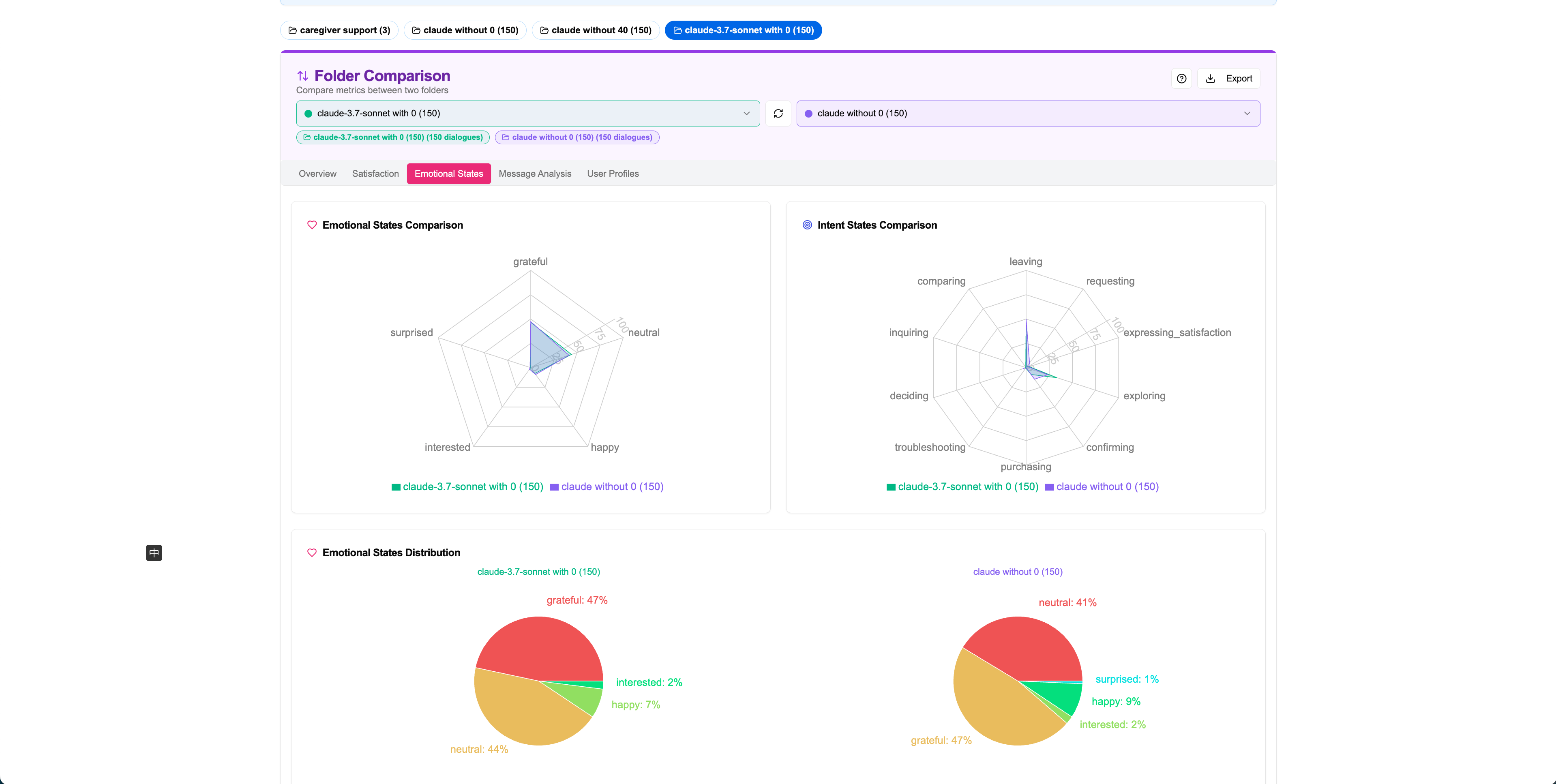
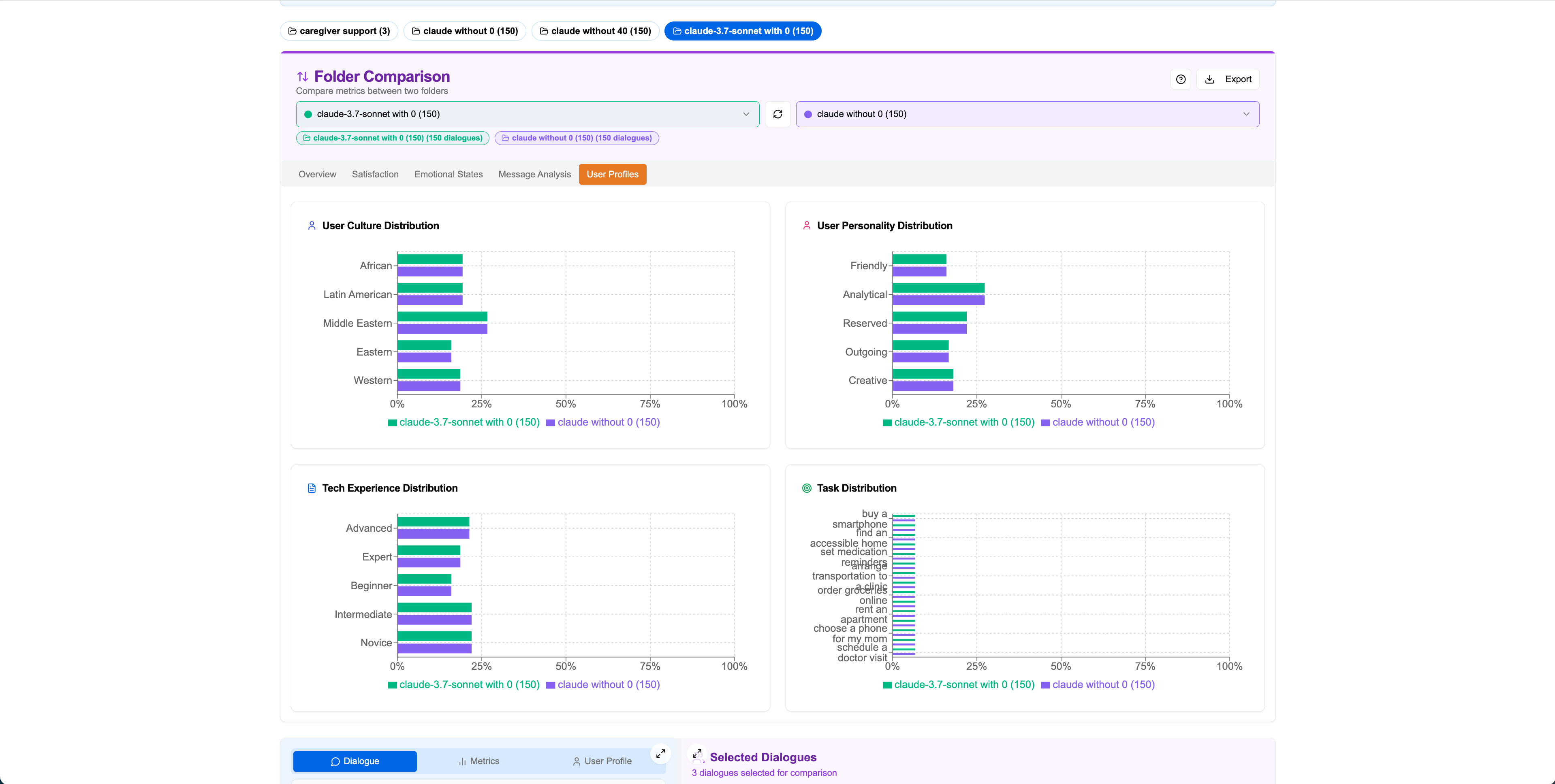
User Profile Comparison
🚀 Quick Navigation Summary
Main Features:
- • Upload and organize dialogue data
- • Analyze individual user interactions
- • Compare multiple dialogues side-by-side
- • Folder-level statistical analysis
Navigation Tips:
- • Use Grid View for overview
- • Switch to Split View for comparison
- • Hover over tooltips for metric details
- • Export results for further analysis
Key Features
- •Grid View for folder overview
- •Split View for detailed analysis
- •Folder comparison capabilities
- •Upload JSON files or folders
- •Export analysis results
Analysis Views
- 📊Satisfaction metrics and trends
- 😊Emotional state tracking
- 🎯Intent classification analysis
- 👤User profile visualization
- 💬Turn-by-turn dialogue breakdown
Usage Workflow
Gratitude is extended to Yifan Zeng for valuable support and constructive suggestions that significantly contributed to this work. Deep appreciation is also given to all friends for their continuous encouragement and support.
Special thanks are given to Cookie (Yaoyao's dog) 🐕 and Lucas (Yaoyao's cat) 🐱 for their loyal companionship throughout this journey.
$ echo "Research paper on intent triggerability in task-oriented dialogue"
Last updated: 2025-05-31 |Status: Open-source